Chondrosarcoma of the skull base
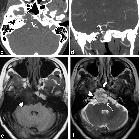







Chondrosarcomas of the base of the skull are rare compared with other skull base tumors but are an important differential diagnosis as surgical resection and management are affected by the preoperative diagnosis.
Epidemiology
Chondrosarcomas of the base of the skull make up only a small fraction of all chondrosarcomas (head and neck chondrosarcomas in one series making up only 7%). They are an even smaller proportion of intracranial neoplasms (making up only ~ 0.2% of all intracranial neoplasms in one series).
Risk factors
The vast majority of chondrosarcomas of the base of the skull are sporadic, however, some predisposing conditions are reported, and include:
- previous trauma/fractures
- Ollier disease
- Maffucci syndrome
Clinical presentation
Patients usually present due to mass effect, either on adjacent brain, brainstem, cranial nerves or (if extension inferiorly) structures of the superior neck.
Pathology
They are thought to arise from embryonal rest cells (remember that the base of skull forms via endochondral ossification).
Location
- petro-occipital synchondrosis (most common)
- sphenoethmoidal junction
- sella turcica
- other rare sites that have been reported (presumably from metaplasia) include:
The majority of chondrosarcomas of the base of the skull are located off the midline (82% in one series) a helpful sign compared to chordomas which are usually midline.
Local extension is common, extending intracranially, into the cavernous sinuses, paranasal sinuses and soft tissues beneath the base of the skull.
Radiographic features
Chondrosarcomas of the base of skull follow the same general imaging characteristics of chondrosarcomas elsewhere – see generic chondrosarcoma article. Importantly CT and MRI are complementary, the former exquisitely delineating the relationship to the skull base and showing calcification within the mass, whereas the later giving important information of signal intensity and relationship to neural structures.
Plain radiograph
Only of historical interest, skull x-rays were important in the diagnosis of these lesions and demonstrated lytic lesions in 50% and calcifications in approximately 60%. As such the differentiation of chondrosarcomas from other skull base tumors was very difficult prior to cross-sectional imaging.
CT
CT with thin triplanar bone algorithm images is important is confirming bony involvement and demonstrating calcification of the tumor, often in characteristic rings and arcs.
MRI
- T1: low signal
- T2: high signal
- SWI/GRE: calcifications show low signal
- T1 C+ (Gd)
- usually heterogeneous enhancement
- fat saturation should be employed to better delineate inferior component
Treatment and prognosis
Chondrosarcomas are relatively slow growing but locally aggressive. Local resection is often the treatment of choice. Radiotherapy may sometimes be employed although sensitivity is thought to be minimal. Metastatic spread is uncommon.
Differential diagnosis
Imaging differential considerations include lesions of the petrous apex. One should also consider specifically:
- chordoma
- usually midline projecting posteriorly
- meningioma
- usually not high T2 signal
- calcification pattern usually not chondroid
- metastases
- calcification not as common
- more destructive
- nasopharyngeal carcinoma
- calcification uncommon
- epicenter in the nasopharynx
- pituitary macroadenoma
- calcification uncommon
- centered on pituitary fossa
- cavernous sinus hemangioma
- also high T2 signal but usually homogeneous
- no calcification
Siehe auch:
- Meningeom
- Chondrosarkom
- Makroadenom Hypophyse
- Chordom
- Nasopharynxkarzinom
- Tumoren der Schädelbasis
- Chondrosarkom des Clivus
und weiter:


 Assoziationen und Differentialdiagnosen zu Chondrosarkom der Schädelbasis:
Assoziationen und Differentialdiagnosen zu Chondrosarkom der Schädelbasis:






